안녕하세요 OCR이라는 거 들어보셨나요?저도 처음 들어봐요
OCR은 광학식 문자 판독으로, 문자의 영상을 이미지 스캐너로 획득해 기계를 읽을 수 있는 문자로 변환하는 것이라고 하는데,
어쨌든 이미지 내의 텍스트를 추출할 수 있게 해주는 기능도 여기에 속한다고 할 수 있겠죠.
그리고 이러한 기능을 구글 드라이브에서도 가능하다는 사실!바로 시도해 봤어요.
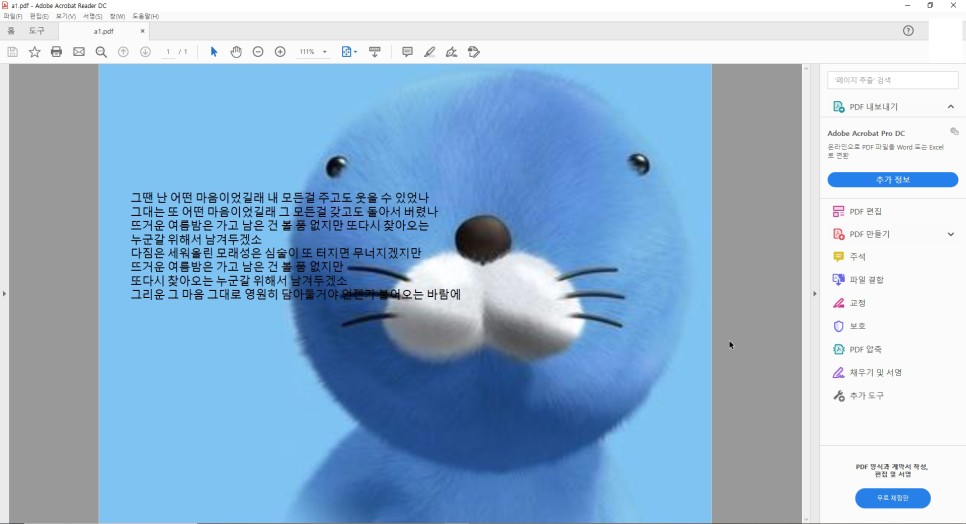
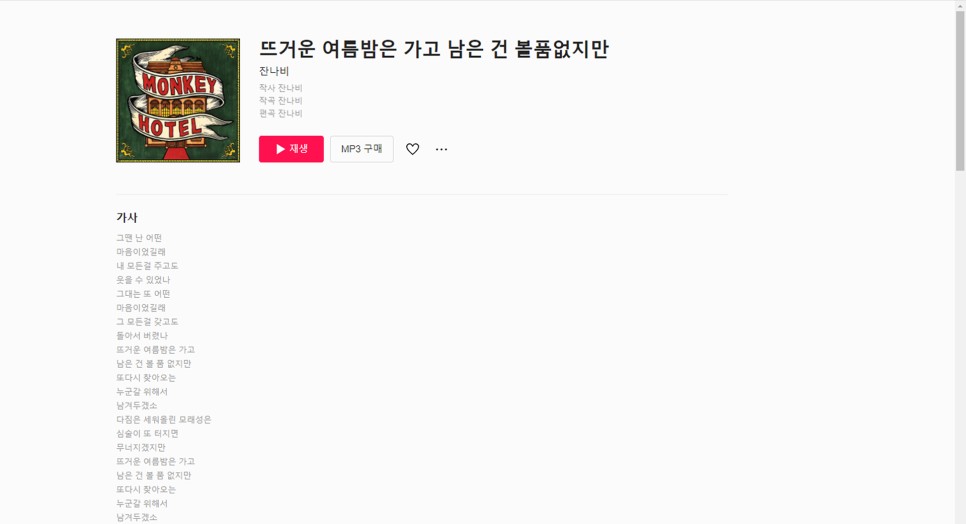
‘잔나비의 뜨거운 여름밤은 가고’ 나머지는 맛없는 가사를 준비해봤습니다
가사 중에 일부만 가져와서 그냥 변환하면 재미없을 것 같아서 보노보노도 맨 뒤에 넣어서 PDF를 만들어 줬어요
이 방법에서는 PDF 와 JPG 등의 화상의 모두 가능하고, PDF 의 화상에서 텍스트를 추출합니다.
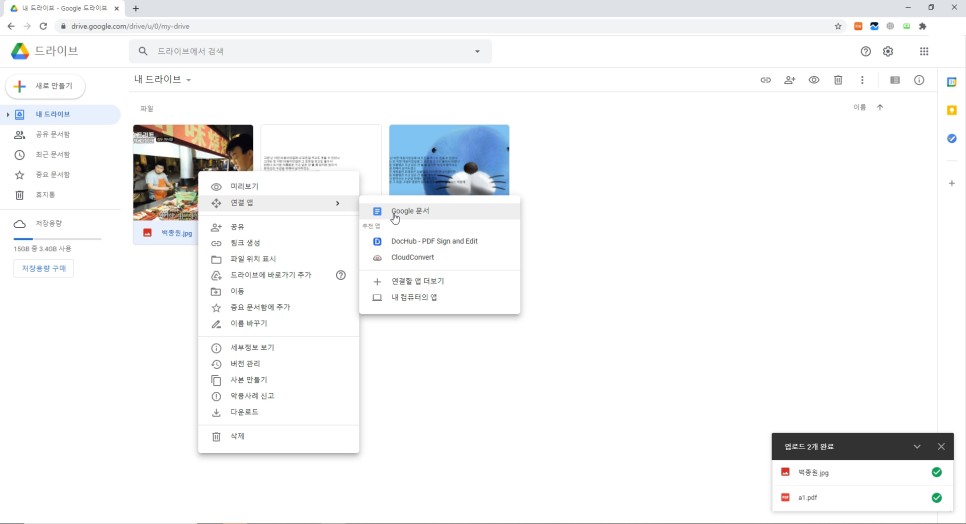
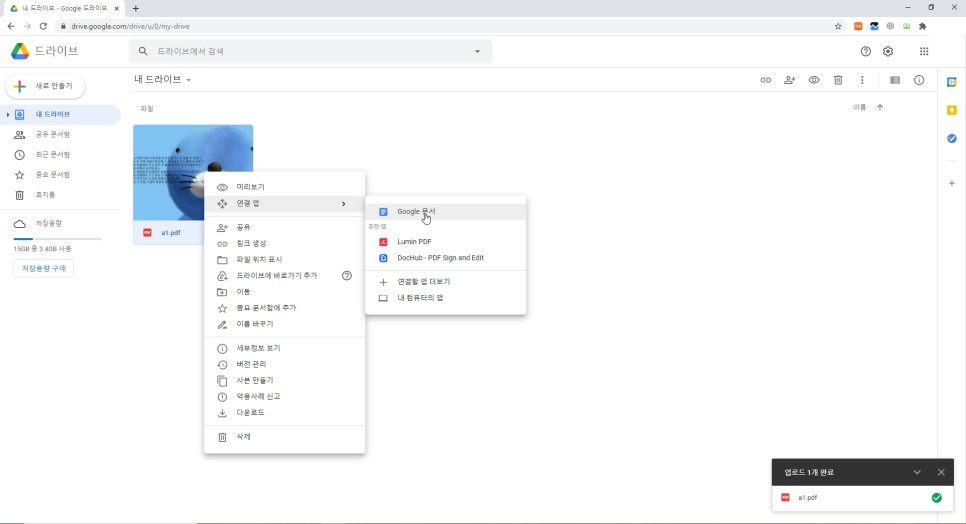
그리고 구글 드라이브에 진입한 후 이미지를 우클릭하고 접속 앱, 구글 문서를 순서대로 누르면
끝!

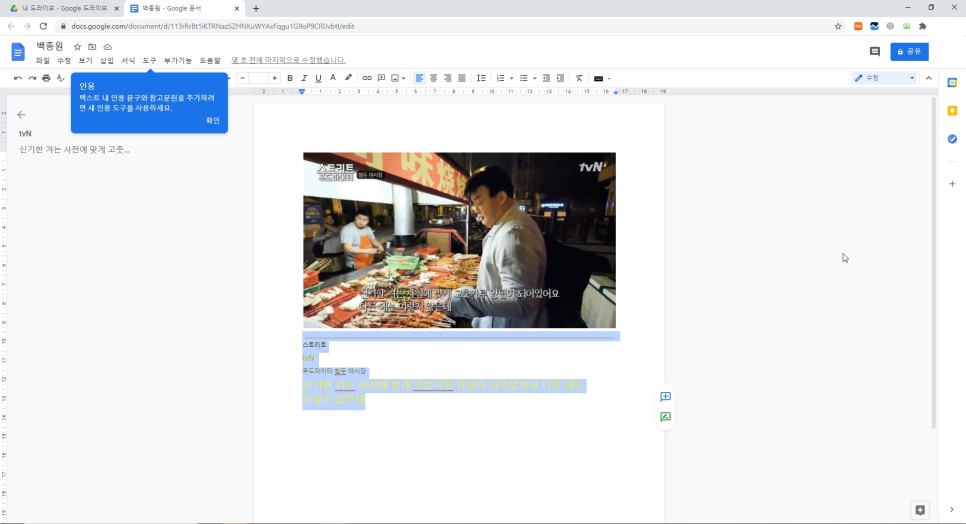
이렇게 글씨가 금방 나온 걸 볼 수 있어요
물론 엔터키까지는 안 맞췄지만 그래도 어느 정도 띄어쓰기 전까지는 다 합쳐서 글자가 나와 있었어요.
비교!
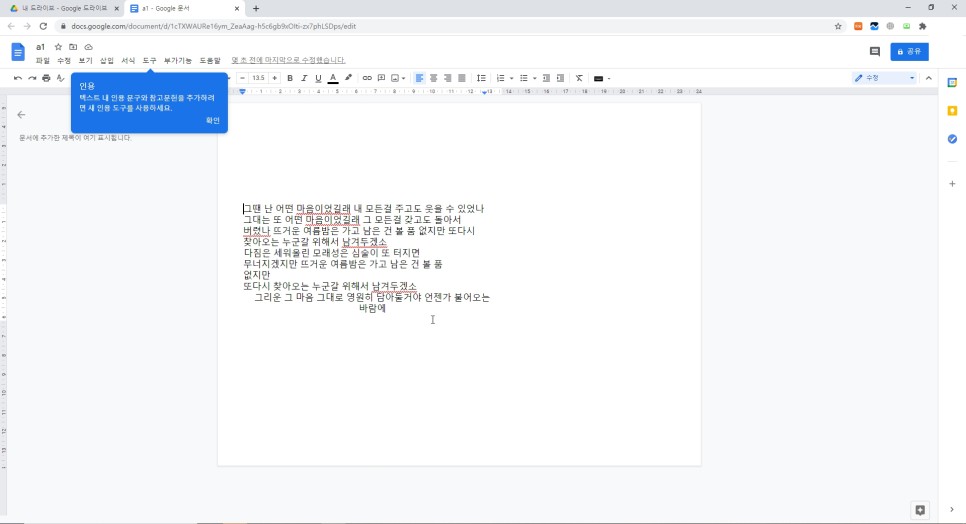
PDF 내에서 글자 뒤에 보노보노의 파란색이 들어간 부분까지 완벽하게 텍스트를 인쇄한 것입니다.

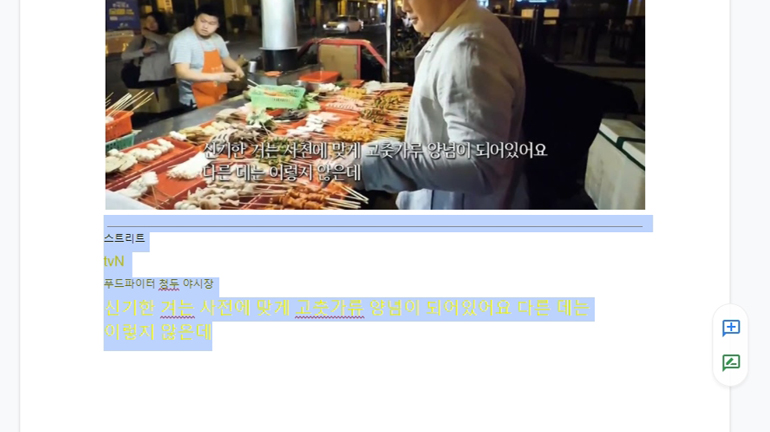
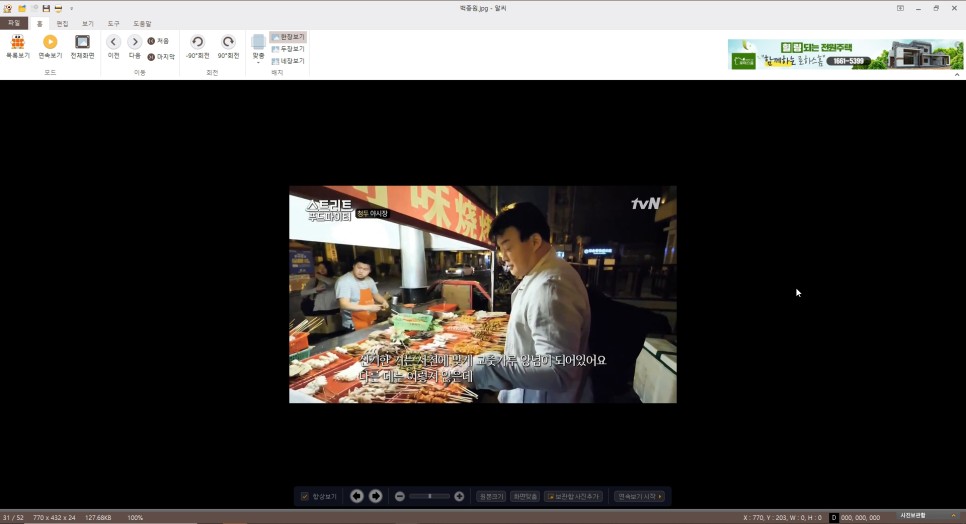
다음은 이미지부터 글자를 뽑아보겠습니다이를 위해 작년에 재미있게 본 스트리트 푸드 파이터의 이미지를 찾아 보았습니다.
글씨와 음식이 겹쳐 난이도가 어려울 것 같아요.

구글 드라이브에 넣고 오른쪽 클릭 – 접속 앱 – 구글 문서를 클릭하면
이렇게문자로변환이되는데요.그런데 어째서 글씨에 색이 들어가서 나왔는지 의문………
확실히 음식이랑 겹치니까
신기한 거 -> 신기한 거 -> 고추장류
조금씩 틀린 부분이 있었어요.하지만 당연히 읽고 이해하는 데는 전혀 문제가 없고
제가 신경도 쓰지 않았던 tvN 로고 등 세부적인 부분도 바뀌었습니다.
사실 굳이 이런 방법을 쓰지 않아도 다양한 프로그램이나 어플리케이션에서 OCR 기술을 사용할 수 있는데
그래도 무설치하고 안전하고 빠르게 사용할 수 있다는 점이 구글 드라이브로 영상이나 PDF 문자를 추출하는 방법의 장점이라고 생각합니다.
그럼 이상으로 화상, PDF에서 텍스트 변환 방법에 대한 포스팅을 마치겠습니다!